本文为操作系统复习笔记,临时上传以供移动端阅读。
[TOC]
Linux Shell
可以通过 Shell 请求内核提供服务,Bash 正是 Shell 的一种。
基础
1. echo命令
用于字符串的输出。可以使用 echo 实现更复杂的输出格式控制。
1 | $ echo "It is a test" |
打印变量变量值:
1 |
|
结果重定向至文件。
1 | echo "It is a test" > myfile |
2. 历史命令
(1) 历史命令查看
使用 history 命令。历史命令默认存在 ~/.bash_history 文件中
(2) 历史命令重复调用
- 使用上下箭头调用。
- 使用 “!n” 重复执行第 n 条历史命令(history 命令结果中每个命令都有一个编号)。
- 使用 “!!” 重复执行上一条历史命令。
- 使用 “!字符串” 重复执行最后一条以该字符串开头的命令。
3. 命令与文件补全
命令补全是按照 PATH 环境变量所定义的路径查找命令的,而文件补全是按照文件位置查找文件的。
4. 命令别名
命令格式:
1 | $ alias # 查询已有别名 |
查看系统已有别名。
1 | [nano@localhost ~]$ alias |
命令别名的优先级高于命令本身。bash 中别名是临时的,永久生效需要把别名写入环境变量配置文件 ~/.bashrc 中。
5. 快捷键
- Tab:命令和文件名补全
- Ctrl+C:中断正在运行的程序
- Ctrl+D:结束键盘输入(End Of File,EOF)
- Ctrl+E:光标移动到命令行结尾
- Ctrl+L:清屏
- Ctrl+U:删除或剪切光标之前的命令
- Ctrl+K:删除或剪切光标之后的命令
- Ctrl+S:暂停屏幕输出
- Ctrl+Q:恢复屏幕输出
6. 指令搜索与执行顺序
命令的搜索与执行的顺序如下:
- 以绝对或相对路径来执行指令,例如 /bin/ls 或者 ./ls ;
- 由别名找到该指令来执行;
- 由 Bash 内置的指令来执行;
- 按 $PATH 变量指定的搜索路径的顺序找到第一个指令来执行。
7. 多命令顺序执行
当需要一次执行多个命令的时候,命令之间需要用连接符连接,不同的连接符有不同的效果。
(1) 符号 ;
格式:命令1 ; 命令2
没有任何逻辑关系的连接符。当多个命令用分号连接时,各命令之间的执行成功与否彼此没有任何影响,都会一条一条执行下去。前面执行出错后面也会执行。
(2) 符号 &&
格式:命令1 && 命令2
逻辑与,当用此连接符连接多个命令时,前面的命令执行成功,才会执行后面的命令,前面的命令执行失败,后面的命令不会执行。
Bash 的预定义变量 “$?” 表示上一条指令的执行结果,值为 0 表示执行正确,非 0 表示执行错误。
&& 可以用于连续操作。比如安装一个软件的多个流程顺序执行。
(3) 符号 ||
格式:命令1 || 命令2
逻辑或,当用此连接符连接多个命令时,前面的命令执行成功,则后面的命令不会执行。前面的命令执行失败,后面的命令才会执行。
判断一个命令是否正确执行:
1 | $ 命令 && echo "yes" || echo "no" |
(4) 符号 |
管道符,当用此连接符连接多个命令时,前面命令执行的正确输出,会交给后面的命令继续处理。若前面的命令执行失败,则会报错,若后面的命令无法处理前面命令的输出,也会报错。
例子:
1 | ls | grep *.txt |
8. Shell脚本
(1) 概述
第一行应该是
1 |
(2) 脚本运行
- 赋予执行权限,直接运行。
1 | $ chmod 755 hello.sh # 增加执行权限 |
- 通过 Bash 调用运行脚本。
1 | $ bash hello.sh |
9. sudo
sudo 允许一般用户使用 root 可执行的命令,不过只有在 /etc/sudoers 配置文件中添加的用户才能使用该指令。
10. 管道符
管道是将一个命令的标准输出作为另一个命令的标准输入,在数据需要经过多个步骤的处理之后才能得到想要的内容时就可以使用管道。在命令之间使用 ==| 分隔==各个管道命令。
1 | $ ls -al /etc | less |
11. 通配符
| 符号 | 含义 |
|---|---|
| ? | 匹配任意一个字符 |
| ***** | 匹配 0 个或任意多个字符 |
| [] | 匹配括号中的任意一个字符 |
| [-] | 匹配括号中的任意一个字符,- 代表范围 |
| [^] | 逻辑非,匹配不在括号中的任意一个字符 |
例子:
1 | $ rm -rf * |
12. Bash中的特殊符号
| 符号 | 含义 |
|---|---|
| ‘’ | 单引号,在单引号中所有的特殊符号都没有了特殊的意义。就是一个普通字符串了。 |
| “” | 双引号,在双引号中 “$”、”`” 和 “\“,分别表示”调用变量的值”、”引用命令”、“转移符”的含义 |
| `` | 反引号,反引号括起来的内容是系统命令,在 bash 中会优先执行,和 $() 效果一样,不过反引号容易看错 |
| $() | 引用系统命令 |
| () | 用于一串命令执行时,() 中的命令会在子 shell 中执行 |
| {} | 用于一串命令执行时,{} 中的命令会在当前 shell 中执行,也可以用于变量变形与替换 |
| $ | 用于调用变量的值,如需要调用变量 name 的值时,需要用 $name 的方式得到变量的值 |
13. Vim
Vim 三个模式:
- 一般指令模式(Command mode):VIM 的默认模式,可以用于移动游标查看内容;
- 编辑模式(Insert mode):按下 “i” 等按键之后进入,可以对文本进行编辑;
- 指令列模式(Bottom-line mode):按下 “:” 按键之后进入,用于保存退出等操作。
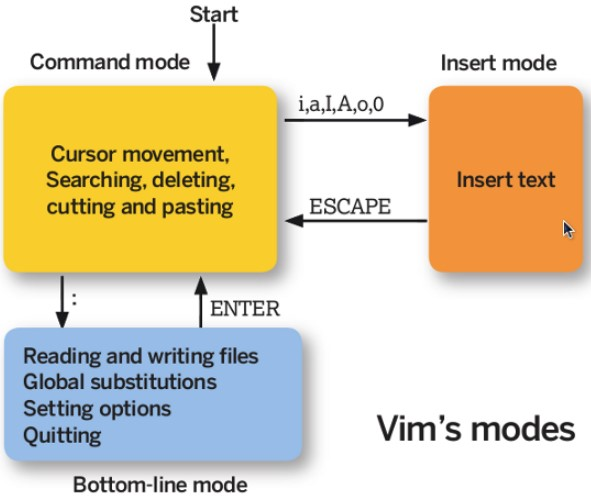
在指令列模式下,有以下命令用于离开或者保存文件。
| 命令 | 作用 |
|---|---|
| :w | 写入磁盘 |
| :w! | 当文件为只读时,强制写入磁盘。到底能不能写入,与用户对该文件的权限有关 |
| :q | 离开 |
| :q! | 强制离开不保存 |
| :wq | 写入磁盘后离开 |
| :wq! | 强制写入磁盘后离开 |
变量操作
1. 概述
对一个变量赋值直接使用 = 号。
对变量取用需要在变量前加上 $ ,也可以用 ${} 的形式。输出变量可使用 echo 命令。
1 | $ x=abc |
变量内容如果有空格,必须使用双引号或者单引号。
- 双引号内的特殊字符可以保留原本特性,例如 x=”lang is $LANG”,则 x 的值为 lang is zh_TW.UTF-8;
- 单引号内的特殊字符就是特殊字符本身,例如 x=’lang is $LANG’,则 x 的值为 lang is $LANG。
可以使用 `指令` 或者 ==$(指令)== 的方式将指令的执行结果赋值给变量。例如 version=$(uname -r),则 version 的值为 4.15.0-22-generic。
可以使用 ==export== 命令将自定义变量转成环境变量,环境变量可以在子程序中使用,所谓子程序就是由当前 Bash 而产生的子 Bash。
Bash 的变量可以声明为数组和整数数字。注意数字类型没有浮点数。如果不进行声明,默认是字符串类型。变量的声明使用 declare 命令:
1 | $ declare [-aixr] variable |
使用 [ ] 来对数组进行索引操作:
1 | $ array[1]=a |
如果需要增加变量值,可以进行变量叠加。
2. 变量类型
主要有四种变量类型。
(1) 用户自定义变量
对一个变量赋值直接使用 =。但是等号左右 不能有空格。自定义变量仅在当前 Shell 生效。
使用 $ 变量名 提取变量内容。
删除自定义变量可以用 unset 命令。
(2) 环境变量
可以使用 export 命令将自定义命令变为环境变量。环境变量可在当前 Shell 和所有子 Shell 生效。
系统默认的环境变量如下:
1 | XDG_SESSION_ID=217 |
重要的环境变量有。
① PATH 变量:系统查找命令的路径
可以在环境变量 PATH 中声明可执行文件的路径,路径之间用 : 分隔。
输出 PATH 变量。
1 | [nano@localhost ~]$ echo $PATH |
可以将自己的 sh 文件加入到上述目录中,或者使用变量叠加的方式将 sh 文件的路径加到 PATH 中,即可通过文件名执行。
1 | PATH="$PATH":/my/sh |
但是这样只是临时生效,永久生效需要写入环境变量配置文件中。
② PS1 变量:命令提示符设置
③ LANG 语系变量
(3) 位置参数变量
主要是向脚本中传递数据,变量名不能自定义,变量作用是固定的。
| 变量 | 含义 |
|---|---|
| $n | $0 代表命令本身,$1-9 代表接受的第 1-9 个参数,10 以上需要用 {} 括起来,比如 ${10} 代表接收的第 10 个参数 |
| $* | 代表接收所有的参数,将所有参数看作一个整体 |
| $@ | 代表接收的所有参数,将每个参数区别对待 |
| $# | 代表脚本接收的参数个数 |
例子:
1 | [root@localhost sh]$ vi param_test.sh |
(4) 预定义变量
常见预定义变量:
| 变量 | 含义 |
|---|---|
| $$ | 当前进程给脚本的 PID 号 |
| $! | 后台运行的最后一个进程的 PID 号 |
| $? | 用于返回上一条命令是否成功执行。如果成功执行,将返回数字 0,否则返回非零数字(通常情况下都返回数字1)。 |
3. 变量查看
set 命令可以查看系统中的所有变量(含环境变量)。
env 命令查看系统环境变量(仅环境变量)。
4. 环境变量配置文件
使配置文件生效:source 配置文件 或 . 配置文件 。
环境变量配置文件中主要是定义对系统的操作环境生效的默认环境变量,比如:PATH, PS1, HOSTNAME 等。
1 | /etc/profile |
上面一共 5 个配置文件,在 /etc 目录下的三个文件如果改变,所有用户都要生效,另外 2 个只对当前用户生效。
这些配置文件按照一定的流程进行加载调用,进而对不同的变量进行设置。
销时生效的环境变量配置文件:~/.bash_logout,默认是空的。
历史命令的配置文件:~/.bash_history。
远程终端登录信息:/etc/issue.net,但是这个文件中的默认不生效,由 ssh 的配置文件 /etc/ssh/sshd_config,加入Banner /etc/issue.net行,重启SSH服务才能生效。
数据流重定向
重定向指的是使用文件代替标准输入、标准输出和标准错误输出。
| 类型 | 代码 | 运算符 |
|---|---|---|
| 标准输入 (stdin) | 0 | < 或 << |
| 标准输出 (stdout) | 1 | > 或 >> |
| 标准错误输出 (stderr) | 2 | 2> 或 2>> |
使用一个箭头表示以覆盖的方式重定向,而有两个箭头的表示以追加的方式重定向。
可以将不需要的标准输出以及标准错误输出重定向到 /dev/null,相当于扔进垃圾箱。
如果需要将标准输出以及标准错误输出同时重定向到一个文件,需要将某个输出转换为另一个输出,例如 2>&1 表示将标准错误输出转换为标准输出。
1 | $ find /home -name .bashrc > list 2>&1 |
提取与转换指令
1. grep命令
g/re/p(globally search a regular expression and print),使用正则表示式进行全局查找并打印。
1 | $ grep [-acinv] [--color=auto] 搜寻字符串 filename |
示例:把含有 the 字符串的行提取出来(注意默认会有 –color=auto 选项,因此以下内容在 Linux 中有颜色显示 the 字符串)
1 | grep -n 'the' regular_express.txt |
因为 { 和 } 在 shell 是有特殊意义的,因此必须要使用转义字符进行转义。
1 | $ grep -n 'go\{2,5\}g' regular_express.txt |
2. cut命令
cut 对数据进行切分,取出想要的部分。切分过程一行一行地进行。
1 | $ cut |
示例 1:last 显示登入者的信息,取出用户名。
1 | $ last |
示例 2:将 export 输出的信息,取出第 12 字符以后的所有字符串。
1 | $ export |
cut 命令不能很好的识别空格符,如果需要,用 awk。
3. 字符转换指令
tr 用来删除一行中的字符,或者对字符进行替换。
1 | $ tr [-ds] SET1 ... |
示例,将 last 输出的信息所有小写转换为大写。
1 | $ last | tr '[a-z]' '[A-Z]' |
col 将 tab 字符转为空格字符。
1 | $ col [-xb] |
expand 将 tab 转换一定数量的空格,默认是 8 个。
1 | $ expand [-t] file |
join 将有相同数据的那一行合并在一起。
1 | $ join [-ti12] file1 file2 |
paste 直接将两行粘贴在一起。
1 | $ paste [-d] file1 file2 |
4. awk命令
是由 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 创造,awk 这个名字就是这三个创始人名字的首字母。
awk 每次处理一行,处理的最小单位是字段,每个字段的命名方式为:$n,n 为字段号,从 1 开始,$0 表示一整行。
示例:首先取出最近五个登录用户的用户名和 IP
1 | $ last -n 5 |
1 | $ last -n 5 | awk '{print $1 "\t" $3}' |
可以根据字段的某些条件进行匹配,例如匹配字段小于某个值的那一行数据。
1 | $ awk '条件类型 1 {动作 1} 条件类型 2 {动作 2} ...' filename |
示例:/etc/passwd 文件第三个字段为 UID,对 UID 小于 10 的数据进行处理。
1 | $ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}' |
awk 变量:
| 变量名称 | 代表意义 |
|---|---|
| NF | 每一行拥有的字段总数 |
| NR | 目前所处理的是第几行数据 |
| FS | 用户定义的分隔字符,默认是空格键 |
示例:显示正在处理的行号以及每一行有多少字段:
1 | $ last -n 5 | awk '{print $1 "\t lines: " NR "\t columns: " NF}' |
5. sed命令
sed 是一种流编编器,它是文本处理中非常中的工具,能够完美的配合正则表达式便用,功物能不同凡响。sed 主要是用来将数据进行选取、替换、删除、新增的命令。sed 会根据脚本命令来处理文本文件中的数据,这些命令要么从命令行中输入,要么存储在一个文本文件中,此命令执行数据的顺序如下:
- 每次仅读取一行内容;
- 根据提供的规则命令匹配并修改数据。注意,sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
- 将执行结果输出。
当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕。
sed 命令的基本格式如下:
1 | [root@localhost ~]$ sed [选项] [脚本命令] 文件名 |
该命令常用的选项及含义,如下表所示。
| 选项 | 含义 |
|---|---|
| -e 脚本命令 | 该选项会将其后跟的脚本命令添加到已有的命令中。 |
| -f 脚本命令文件 | 该选项会将其后文件中的脚本命令添加到已有的命令中。 |
| -n | 默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。 |
排序指令
sort 用于排序。
1 | $ sort [-fbMnrtuk] [file or stdin] |
示例:/etc/passwd 文件内容以 : 来分隔,要求以第三列进行排序。
1 | $ cat /etc/passwd | sort -t ':' -k 3 |
uniq 可以将重复的数据只取一个。
1 | $ uniq [-ic] |
示例:取得每个人的登录总次数
1 | $ last | cut -d ' ' -f 1 | sort | uniq -c |
条件判断test指令
test 命令在 shell 脚本中经常以中括号 [] 的形式出现,而且在脚本中使用字母来表示比符号表示更专业,出错率更低。
| 测试标志 | 代表意义 |
|---|---|
| 文件名、文件类型 | |
| -e | 该文件名是否存在 |
| -f | 该文件名是否存在且为 file |
| -d | 该文件名是否存在且为目录 |
| -b | 该文件名是否存在且为一个 block |
| -c | 该文件名是否存在且为一个 character device 设备 |
| -S | 该文件名是否存在且为一个 socket 文件 |
| -p | 该文件名是否存在且为一个 FIFO(pipe)文件 |
| -L | 该文件名是否存在且为一个连接文件 |
| 文件权限检测 | |
| -r | 检测文件名是否存在且具有“可读”权限 |
| -w | 检测文件名是否存在且具有“可写”权限 |
| -x | 检测文件名是否存在且具有“可执行”权限 |
| -u | 检测文件名是否存在且具有“SUID”权限 |
| -g | 检测文件名是否存在且具有“SGID”权限 |
| -k | 检测文件名是否存在且具有“Sticky bit”权限 |
| -s | 检测文件名是否存在且为“非空白文件” |
| 两个文件的比较 | |
| -nt | (newer than)判断 file1 是否比 file2 新 |
| -ot | (older than)判断 file 是否比 file2 旧 |
| -ef | 判断 file1 与 file2 是否为同一个文件,可用在判断 hard link 上 |
| 数字之间的判定 | |
| -eq | equal |
| -ne | not equal |
| -gt | greater than |
| -lt | less than |
| -ge | greater than or equal |
| -le | less than or equal |
| 判断字符串的数据 | |
| test -z string | 判断字符串是否为 0,若为空返回 true |
| test -n string | 判断字符串是否为 0,若为空返回 false |
| test str1 = str2 | 判断 str1 是否等于 str2,若相等,返回 true |
| test str1 != str2 | 判断 str1 是否等于 str2,若相等,返回 false |
| 多重条件的判断 | |
| -a | 两个条件同时成立,eg:test -r file a test -x file,同时成立返回 true |
| -o | 任何一个条件成立,eg:test -r file o test -x file,同时成立返回 true |
| ! | 反向状态,如 test!-x file,当 file 不具有 x 时,返回 true |
压缩与打包
1. 压缩文件名
Linux 底下有很多压缩文件名,常见的如下:
| 扩展名 | 压缩程序 |
|---|---|
| *.Z | compress |
| *.zip | zip |
| *.gz | gzip |
| *.bz2 | bzip2 |
| *.xz | xz |
| *.tar | tar 程序打包的数据,没有经过压缩 |
| *.tar.gz | tar 程序打包的文件,经过 gzip 的压缩 |
| *.tar.bz2 | tar 程序打包的文件,经过 bzip2 的压缩 |
| *.tar.xz | tar 程序打包的文件,经过 xz 的压缩 |
2. 压缩指令
(1) gzip
gzip 是 Linux 使用最广的压缩指令,可以解开 compress、zip 与 gzip 所压缩的文件。经过 gzip 压缩过,源文件就不存在了。有 9 个不同的压缩等级可以使用。可以使用 zcat、zmore、zless 来读取压缩文件的内容。
1 | $ gzip [-cdtv#] filename |
(2) zip2
提供比 gzip 更高的压缩比。查看命令:bzcat、bzmore、bzless、bzgrep。
1 | $ bzip2 [-cdkzv#] filename |
(3) xz
提供比 bzip2 更佳的压缩比。可以看到,gzip、bzip2、xz 的压缩比不断优化。不过要注意的是,压缩比越高,压缩的时间也越长。查看命令:xzcat、xzmore、xzless、xzgrep。
1 | $ xz [-dtlkc#] filename |
3. 打包
压缩指令只能对一个文件进行压缩,而打包能够将多个文件打包成一个大文件。tar 不仅可以用于打包,也可以使用 gzip、bzip2、xz 将打包文件进行压缩。
1 | $ tar [-z|-j|-J] [cv] [-f 新建的 tar 文件] filename... # 打包压缩 |
| 使用方式 | 命令 |
|---|---|
| 打包压缩 | tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称 |
| 查 看 | tar -jtv -f filename.tar.bz2 |
| 解压缩 | tar -jxv -f filename.tar.bz2 -C 要解压缩的目录 |
其他命令
1. 双向输出重定向
输出重定向会将输出内容重定向到文件中,而 tee 不仅能够完成这个功能,还能保留屏幕上的输出。也就是说,使用 tee 指令,一个输出会同时传送到文件和屏幕上。
1 | $ tee [-a] file |
2. 分区指令
split 将一个文件划分成多个文件。
1 | $ split [-bl] file PREFIX |
3. printf
用于格式化输出。它不属于管道命令,在给 printf 传数据时需要使用 $( ) 形式。
1 | $ printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt) |